A pain in the react: Challenges behind SSR
May 16, 2019 • 19 min read
tl;dr In this post I’ll try to show what, in my opinion, are the current pain points on the common ways to do ssr in React, comparing existing solutions in a didactic way.

First of all, what’s SSR?. SSR is the acronym for server side rendering. On a high level, this means generating the complete web page on the server without having to rely on the client side javascript.
We won’t enter into details of why we’d want to do this, but, it can be mainly motivated by SEO concerns, accessibility or just performance.
Problems behind SSR
If we take a quick look to the react documentation server side rendering might be seen as something quite simple. Just import react-dom/server and call renderToString method. Easy peasy:
const http = require('http');
const ReactDOMServer = require('react-dom/server');
const App = require('./App.js');
const server = http.createServer((req, res) => {
const html = ReactDOMServer.renderToString(
<App />
);
res.send(html);
});
server.listen(8000);Well, sadly this will not work. Mainly because we are used to writing jsx in React, and we tend to forget that it isn’t valid javascript. We could change the <App /> line to use React.createElement but that approach wouldn’t escale for all the App.js file, the rest of the components and css files (it gets worse if a css pre-processor is used). So, here comes the first problem: The need of transpiling server code.

A common practice is dispatching data fetching on the componentDidMount lifecycle. But, do we have that life cycle method on server side?, spoiler: no. Really, it won’t make any sense having componentDidMount on server, remember that renderToString is a synchronous single pass rendering, while on client side, we would call setState after data fetching is done in order to trigger another rendering phase. This difference between life cycles leds to several problems, first of all, how can we determine and fetch data before we render on server side?. And second, how can we share the state (which would have been generated with setState) between server and client?.
Last but not least, on client side we would trigger data fetching with ajax. Something like making a fetch call to an endpoint. This request will have specific information (mainly host information and headers such as the cookie one), how can this be replicated on server side?
To round up, we’ll have to deal with the following issues:
- Generating valid JS code for the server
- Determining data dependencies
- Actually fetching data
- Sharing state
Generating valid JS code for the server
React is known for having a steep configuration in order to get it running. If we check what is considered a hello world example (using create react app) we would realize that we are including like 1300 dependencies . All these dependencies deal with a lot of features and requirements that we probably don’t need, but, you get the point, it isn’t something simple to get react running.

As far as how could we get valid node js code, we’ve got several options:
- Webpack: apply similar building steps as it’s done with the client code
- Babel: transpile the code using babel-cli, no bundling.
There are many more options, we could use another bundlers (or compile with zeit’s ncc), but it doesn’t make much sense to throw new tooling.
Being pedantic, we should not need webpack, babel could be the one and only tool used for generating valid node js code. In fact, webpack will use babel under the hood for transpiling, so we could skip the intermediary. On the nodejs case, bundling isn’t something we need, we can have many files and include them via node’s module system, ie., in a less fancier way, use require.

The problem of the one tool to rule them all approach (ie. only babel) is that generally webpack is doing more tasks that only transpiling. For example, are we using css modules?, so, webpack is doing a name mangling of the classes to renerate unique names via the css loader. Are we using build time constants?, we are probably defining them with webpack’s define plugin. There are more examples of tasks that webpack is performing (static files, etc, etc), but for each of these tasks we’ll have to find a babel preset or plugin that performs this job.
If we stick with the webpack path, although we won’t have the same configuration file for client and server, both files will be very similar, sharing most of its code. Also, most webpack loaders have a sort of explanation of how to use them for server side rendering (for example, css loader has the exportOnlyLocals option ).
Well, returning to our objective, we’ll need to add some packages:
- Webpack (and webpack cli)
- Babel (preset and loaders)
- React (and react dom)
yarn add --dev webpack webpack-cli webpack-node-externals @babel/core @babel/preset-env @babel/preset-react babel-loader
yarn add react react-domYou may be wondering what webpack-node-externals is, well, on node, we don’t want to bundle packages that can be included (require) on runtime (all packages from node_modules and the standard library), webpack-node-externals does exactly that.
Instead of separating build phases of server and client will use webpack’s array configuration:
module.exports = [
// Client configuration
{
mode,
entry: path.join(src, 'client'),
output: {
path: dist,
filename: 'client.js',
},
module: {
rules: [
{
test: /\.js$/,
include: [src],
use: [
{
loader: 'babel-loader',
options: {
presets: [
['@babel/preset-env', { modules: false }],
'@babel/preset-react'
],
},
},
],
},
],
},
},
// Server configuration
{
mode,
target: 'node',
entry: src,
output: {
path: dist,
filename: 'server.js',
},
module: {
rules: [
{
test: /\.js$/,
include: [src],
use: [
{
loader: 'babel-loader',
options: {
presets: [
['@babel/preset-env', { targets: { node: 'current' }}],
'@babel/preset-react'
],
},
},
],
},
],
},
externals: [
nodeExternals(),
],
},
];I won’t enter into details about babel presets: babel-preset-env is the easiest way to support new ECMA syntax and babel-preset-react allow us to write jsx.
Full example can be found here.
So, have we finished?. The quick answer is no. This example was the minimum to get React server side rendering running, it lacks of many features (no css, no static files, no source map, no production optimization, no vendor bundle, no code spliting, etc). Although we could start building a full project from this, I wouldn’t recommend it. Now a days, we will probably use a tool that solves all this configuration, such as razzle, next.js or react-server. The idea of the example was to understand, on a higher level, how these tools work under the hood.
For the following examples we will use razzle to reduce the needed boilerplate.
Determining data dependencies
As I have said before, React on server behaves differently than on client. When calling renderToString, we are doing a sync one pass render. This means that in order to generate the complete page we will have to figure out how to fetch all the needed data before rendering.
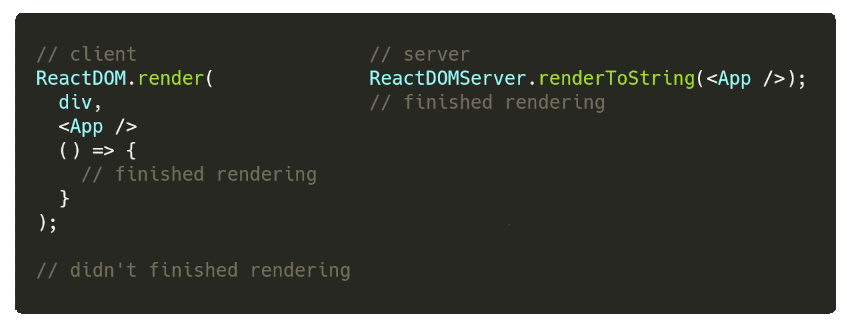
There are mainly two approaches to solve this problem:
- A Page / Route based approach (NextJs’s getInitialProps or Afterjs’s getInitialProps)
- Component tree based approach (Apollo’s getDataFromTree)
The first one relies heavily on using a router that works inside and outside the react world. Firstly, we would define Pages or Routes, ie, React components that will be rendered when a particular url is fetched. This can be done in many ways, eg, NextJs’s uses a filename convention, or we could just have a routes object where urls are mapped to specific components.
It is important to note that we will only take into account data dependencies of pages (or routes), child components will be ignored. This is also highlighted on NextJs’s doc:
Note:
getInitialPropscan not be used in children components. Only inpages.
So, the idea will be something like the following:
- Get the url from the request
- Determine the pages that will be rendered for that url
- Call
getInitialProps(or the data fetching method of the page)
We’ll start writing a routes file in order to define what pages are rendered with each urls:
import Home from './Home';
import Other from './Other';
const routes = [
{
path: '/',
component: Home,
exact: true
},
{
path: '/other',
component: Other,
exact: true
}
];
export default routes;Next step is to determine what pages match the requested url. To achieve this, we’ll use React Router’s matchPath function, and then call the getInitialProps static method if it exists:
server
.get('/*', async (req, res) => {
// Requested url
const url = req.url;
let promise;
routes.some(route => {
const match = matchPath(url, route);
const { getInitialProps } = route.component;
if (match && getInitialProps)
promise = getInitialProps();
return !!match;
});
// XXX: should handle exceptions!
await promise;
// render
});Note: Although, React router has a package which does this job, react-router-config, to keep things simple the example won’t use it.
On client side, we’ll have to add some code to run the getInitialProps method (something like the After component does in afterjs).
For the sake of simplicity, we’ll follow a slightly different approach than afterjs. On the componentDidMount and componentDidUpdate methods, we’ll just call getInitialProps :
class Home extends Component {
static async getInitialProps() {
console.log('Fetching Home!');
}
componentDidMount() {
Home.getInitialProps();
}
componentDidUpdate(prevProps){
// Only fetch data if location has changed
if (this.props.location != prevProps.location)
Home.getInitialProps();
}
render() {
return (
<div className="Home">
This is the home!
</div>
);
}
}Full example can be found here.
On the other hand, Apollo GraphQL uses a tree based approach. This way of determining data dependencies is more declarative, as any component (not only pages) could have them.
The drawback of this solution is that is rather complex (we are kind of doing a pre render to get data dependencies), I won’t enter into too much details, as Apollo’s Blog has a great post explaining how it works. To make a short summary, Apollo has a function called getDataFromTree which walks through the entire React tree checking if components need to fetch information. Before the 2.5 branch, Apollo had a custom walkTree method which somehow reimplements React rendering algorithm (this is explained on the mentioned apollo’s blog post).
Now a days (since Apollo 2.5), the getDataFromTree method uses React-Dom’s renderToStaticMarkup under the hood. The Query component only renders its children when data has been fetched. And renderToStaticMarkup is called until no more information is needed to be fetched. So, Apollo calls renderToStaticMarkup to collect all the promises of the query components. As those components, if they have a data dependency, don’t render its children (bare in mind that fetched data might affect what the children are), renderToStaticMarkup has to be called when those promises are resolved. This process is repeated until no more promises are collected. This approach allows to declare data dependencies on any node in the react tree, but has the performance issue of having to render the tree many times.
Although, we are able to determine, on client and server, what data dependencies we need to fetch, we haven’t actually fetched any data nor shared across client and server!
Actually fetching data
On the previous step, we’ve detected what data is needed, but we haven’t developed a way to actually fetch that data. Going to the basics, fetching data will be a simple ajax call (calling fetch on client side and a node compatible fetch implementation on server side). But, we must bare in mind that on the client side, fetch does some extra jobs under the hood:
const fetch = require('node-fetch');
fetch('/data');
// UnhandledPromiseRejectionWarning: TypeError: Only absolute URLs are supportedApart from the absolute url, the client stores and sends http headers (eg.: Cookie) that we’ll need to forward while doing SSR.

Both APIs, NextJs getInitialProps and AfterJs getInitialProps, implement a similar interface. This method is called with a bunch of parameters:
req: The request object (only server side)res: The response object (only server side)- Location (url) related information
The problem here is that we are left alone when resolving the differences between server and client. Next nor AfterJs provide us a way to solve this. This often led to use a package such as fetch-ponyfill in order to have an isomorphic fetching function which could result in sending unnecessary code to the client and adding a base url (also forwarding request headers) if the req param is present:
// ...
const fetch = require('fetch-ponyfill')();
const Component = () => /* ... */;
Component.getInitialProps = async ({ req }) => {
let url = '/data';
let opts = {};
if (req) {
url = `${req.protocol}://${req.headers.host}${url}`;
opts.headers = req.headers;
}
return fetch(url, opts);
};Note: The simplest way of replicating the ajax request on server side is doing a request to itself, that’s why we are prepending the host to the requested url. This isn’t the most efficient solution, but it just works.
Well, so in order to provide a unified data fetching api, we’ll slightly modify the getInitialProps api adding a fetch function. On server side, this function will take care of adding the base url stuff and headers, while on client side, it will be the default fetch.
import nodeFetch from 'node-fetch';
//...
server
// ...
.get('/*', async (req, res) => {
const fetch = (url, opts = {}) =>
nodeFetch(`${req.protocol}://${req.headers.host}${url}`, {
...opts,
headers: {
...req.headers,
...opts.headers
}
});
// Requested url
const url = req.url;
let promise;
routes.some(route => {
const match = matchPath(url, route);
const { getInitialProps } = route.component;
if (match && getInitialProps)
promise = getInitialProps({ fetch, match });
return !!match;
});
// XXX: should handle exceptions!
await promise;
// ...
});While on client:
class Home extends Component {
static async getInitialProps({ fetch }) {
return fetch('/data')
.then(r => r.json())
}
// ...
componentDidMount() {
Home.getInitialProps({
fetch,
match: this.props.match,
}).then(r => this.setState(r));
}
componentDidUpdate(prevProps){
// Only fetch data if location has changed
if (this.props.location != prevProps.location)
Home.getInitialProps({
fetch,
match: this.props.match,
}).then(r => this.setState(r));
}
// ...
}This concept of not using a global fetch function and relying on the set up to differentiate implementation between server and client could also be used if we have a redux stack. When setting up the store, we could add a middleware which provides the same interface for data fetching but different implementations. A quick example can be achieved using redux-thunk (Note: we could also write a custom middleware and dispatch custom actions):
// createStore.js
import { createStore, applyMiddleware } from 'redux';
import thunk from 'redux-thunk';
import rootReducer from './reducers/index';
export default function (fetch) {
return createStore(
rootReducer,
applyMiddleware(thunk.withExtraArgument(fetch))
);
}
// client
import createStore from './createStore';
const store = createStore(fetch);
// server
import createStore from './createStore';
server
// ...
.get('/*', async (req, res) => {
const fetch = (url, opts = {}) =>
nodeFetch(`${req.protocol}://${req.headers.host}${url}`, {
...opts,
headers: {
...req.headers,
...opts.headers
}
});
const store = createStore(fetch);
// ...
})On any action creator, we will use the third argument as the fetch function:
const actionCreator = (dispatch, getState, fetch) => {
dispatch(loading());
return fetch('/data')
.then(data => {
dispatch(receivedData(data));
});
}If we check Apollo’s GraphQL approach, we will see a similar solution:
server
// ...
.get('/*', (req, res) => {
const client = new ApolloClient({
ssrMode: true,
// Remember that this is the interface the SSR server will use to connect to the
// API server, so we need to ensure it isn't firewalled, etc
link: createHttpLink({
uri: `${req.protocol}://${req.headers.host}`,
credentials: 'same-origin',
headers: {
cookie: req.header('Cookie'),
},
}),
cache: new InMemoryCache(),
});
// ...
});Going back to the example (you can download the full example here), if we run it we’ll have a splash:
Well, although we are fetching data on server side, we are not sharing it with the client nor using it on the server!.
Sharing state
We’ve managed to sort out how to detect what data request we need, actually fetched that data, but we aren’t sharing that state between server and client.
First of all, we’ll have to develop a way to use the initial state generated by the server. For the component, this means initializing its state with a prop instead of an empty object:
class Home extends Component {
// ...
state = this.props.initialState || {};
// ...
}(Yes, we are not reacting to initialState prop change which is considered an anti pattern in react world, but the idea of this example is to portrait the concepts which makes ssr work, not developing a production ready code. Also, initialState should be inmutable, so, taking that precondition here should not be a problem).
The parent component, also, has to pass the initial state:
const App = ({ initialState }) => (
<Switch>
{routes.map(({ path, exact, component: Component }) => (
<Route
key={path}
path={path}
exact={exact}
render={props => (
<Component
initialState={initialState[props.location.pathname]}
{...props}
/>
)}
/>
))}
</Switch>
);Although initialState will only bring data of one component (will only have the value of the resolved promise created by the matched component’s getInitialProps), it’s a dictionary whose key is the url for the fetched data. The reason behind this is just simplifying the code needed to access that data: initialState[props.location.pathname] will return the data if it is the server side fetched component or it will return undefined if it isn’t.
As far as the server is concerned, we will store the resolved value and pass it to the Appcomponent:
server
.get('/*', async (req, res) => {
// ...
const initialState = {
[url]: await promise,
};
const markup = renderToString(
<StaticRouter location={url}>
<App initialState={initialState} />
</StaticRouter>
);
// ...
});We still need to pass the state from the server to the client. To achieve this, we will append a script tag that will attach the initialState to a global variable (eg: window.__INITIAL_STATE__):
res.status(200).send(
`<!doctype html>
<html lang="">
<head>
<!-- ... -->
</head>
<body>
<div id="root">${markup}</div>
<script>
window.__INITIAL_STATE__ = ${JSON.stringify(initialState)};
</script>
</body>
</html>`
);This is the approach suggested by most libraries (Redux, NextJS, Apollo GraphQL). On production, we would probably want to use a safer library for serialization.
And in the client, we will read that variable:
const initialState = window.__INITIAL_STATE__ || {};
hydrate(
<BrowserRouter>
<App initialState={initialState} />
</BrowserRouter>,
document.getElementById('root')
);The full example can be found here
Are we done?
Well, really, no. There are many things left aside. My objective while writing this post was to sort out my ideas of what are the problems while trying to implement a basic react server side rendering app, in a way which could also help somebody else!. Personally, I think that to understand how the tools I use work will allow me to use them in a better way or create out-of-the-box solutions for known problems.
The examples of this post are far from being production code, just to name a few issues:
- The
Homecomponent is the only one that does data fetching. All the needed logic is implemented on that component, clearly this won’t scale. Data fetching code should be abstracted (it’s not the component’s concern!), perhaps high order components (eg:withInitialProps) or render props could be use to encapsulate it. (Well, probably for a non-didactic purpose, it’s better to follow AfterJs / NextJs implementation and put that data-fetching implementation on the page’s parent component) - We haven’t even talk about how to prevent fetching the same resource multiple times if more that one component request it (this would happen when a Apollo-like approach is followed or if multi-level pages, ie children pages, are implemented).
- Avoid the network for local queries: on the examples we have being doing a
fetchtolocalhost, but this is rather inefficient. Apollo GraphQL has a section about how to do this, but in the practice is rather hard to implement it.
This post comes with a deprecation notice.
As I’ve said at the start of the post most of the problems appear because React doesn’t provide us with a standard data fetching solution. We have to implement one of our own on top of the react api. All of this might change with the introduction of Suspense, Concurrent and Cache. The issue is that is not ready yet. React doesn’t support suspense on server side rendering. And on the client it’s only supported to do code splitting via React.lazy. React cache is on its early alpha and many things are prefixed with an unstable. Although there are many experiments out there (such as react ssr prepass or react lightyear), we won’t be able to use them for anything more than playing around with what might be the future. But, let’s cross our fingers that React’s data fetching future might look bright, we just need to await React.suspense().

Personal thoughs by Nicolas Cisco. Mainly programming related stuff.